Database is a collection of related data and data is a collection of facts and figures that can be processed to produce information.
Mostly data represents recordable facts. Data aids in producing information, which is based on facts. For example, if we have data about marks obtained by all students, we can then conclude about toppers and average marks.
A database management system stores data in such a way that it becomes easier to retrieve, manipulate, and produce information.
Query Language − DBMS is equipped with query language, which makes it more efficient to retrieve and manipulate data. A user can apply as many and as different filtering options as required to retrieve a set of data. Traditionally it was not possible where file-processing system was used.
ACID Properties − DBMS follows the concepts of Atomicity, Consistency, Isolation, and Durability (normally shortened as ACID). These concepts are applied on transactions, which manipulate data in a database. ACID properties help the database stay healthy in multi-transactional environments and in case of failure.
Users
A typical DBMS has users with different rights and permissions who use it for different purposes. Some users retrieve data and some back it up. The users of a DBMS can be broadly categorized as follows −

Administrators − Administrators maintain the DBMS and are responsible for administrating the database. They are responsible to look after its usage and by whom it should be used. They create access profiles for users and apply limitations to maintain isolation and force security. Administrators also look after DBMS resources like system license, required tools, and other software and hardware related maintenance.
Designers − Designers are the group of people who actually work on the designing part of the database. They keep a close watch on what data should be kept and in what format. They identify and design the whole set of entities, relations, constraints, and views.
End Users − End users are those who actually reap the benefits of having a DBMS. End users can range from simple viewers who pay attention to the logs or market rates to sophisticated users such as business analysts.
3-tier Architecture
A 3-tier architecture separates its tiers from each other based on the complexity of the users and how they use the data present in the database. It is the most widely used architecture to design a DBMS.

Database (Data) Tier − At this tier, the database resides along with its query processing languages. We also have the relations that define the data and their constraints at this level.
Application (Middle) Tier − At this tier reside the application server and the programs that access the database. For a user, this application tier presents an abstracted view of the database. End-users are unaware of any existence of the database beyond the application. At the other end, the database tier is not aware of any other user beyond the application tier. Hence, the application layer sits in the middle and acts as a mediator between the end-user and the database.
User (Presentation) Tier − End-users operate on this tier and they know nothing about any existence of the database beyond this layer. At this layer, multiple views of the database can be provided by the application. All views are generated by applications that reside in the application tier.
Entity-Relationship Model
Entity-Relationship (ER) Model is based on the notion of real-world entities and relationships among them. While formulating real-world scenario into the database model, the ER Model creates entity set, relationship set, general attributes and constraints.
ER Model is best used for the conceptual design of a database.
ER Model is based on −
Entities and their attributes.
Relationships among entities.
These concepts are explained below.
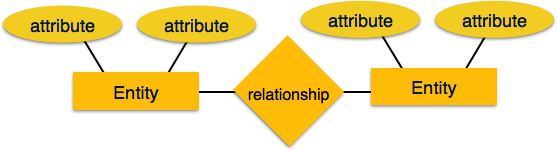
Entity − An entity in an ER Model is a real-world entity having properties called attributes. Every attribute is defined by its set of values called domain. For example, in a school database, a student is considered as an entity. Student has various attributes like name, age, class, etc.
Relationship − The logical association among entities is called relationship. Relationships are mapped with entities in various ways. Mapping cardinalities define the number of association between two entities.
Mapping cardinalities −
one to one
one to many
many to one
many to many
Relational Model
The most popular data model in DBMS is the Relational Model. It is more scientific a model than others. This model is based on first-order predicate logic and defines a table as an n-ary relation.

The main highlights of this model are −
Data is stored in tables called relations.
Relations can be normalized.
In normalized relations, values saved are atomic values.
Each row in a relation contains a unique value.
Each column in a relation contains values from a same domain.
Database Schema
A database schema is the skeleton structure that represents the logical view of the entire database. It defines how the data is organized and how the relations among them are associated. It formulates all the constraints that are to be applied on the data.
A database schema defines its entities and the relationship among them. It contains a descriptive detail of the database, which can be depicted by means of schema diagrams. It’s the database designers who design the schema to help programmers understand the database and make it useful.

A database schema can be divided broadly into two categories −
Physical Database Schema − This schema pertains to the actual storage of data and its form of storage like files, indices, etc. It defines how the data will be stored in a secondary storage.
Logical Database Schema − This schema defines all the logical constraints that need to be applied on the data stored. It defines tables, views, and integrity constraints.
Database Instance
Database schema is the skeleton of database. It is designed when the database doesn't exist at all. Once the database is operational, it is very difficult to make any changes to it. A database schema does not contain any data or information.
A database instance is a state of operational database with data at any given time. It contains a snapshot of the database. Database instances tend to change with time. A DBMS ensures that its every instance (state) is in a valid state, by diligently following all the validations, constraints, and conditions that the database designers have imposed.
Data Independence
A database system normally contains a lot of data in addition to users’ data. For example, it stores data about data, known as metadata, to locate and retrieve data easily. It is rather difficult to modify or update a set of metadata once it is stored in the database. But as a DBMS expands, it needs to change over time to satisfy the requirements of the users. If the entire data is dependent, it would become a tedious and highly complex job.

Metadata itself follows a layered architecture, so that when we change data at one layer, it does not affect the data at another level. This data is independent but mapped to each other.
Logical Data Independence
Logical data is data about database, that is, it stores information about how data is managed inside. For example, a table (relation) stored in the database and all its constraints, applied on that relation.
Logical data independence is a kind of mechanism, which liberalizes itself from actual data stored on the disk. If we do some changes on table format, it should not change the data residing on the disk.
Physical Data Independence
All the schemas are logical, and the actual data is stored in bit format on the disk. Physical data independence is the power to change the physical data without impacting the schema or logical data.
For example, in case we want to change or upgrade the storage system itself − suppose we want to replace hard-disks with SSD − it should not have any impact on the logical data or schemas.
Entity
An entity can be a real-world object, either animate or inanimate, that can be easily identifiable. For example, in a school database, students, teachers, classes, and courses offered can be considered as entities. All these entities have some attributes or properties that give them their identity.
An entity set is a collection of similar types of entities. An entity set may contain entities with attribute sharing similar values. For example, a Students set may contain all the students of a school; likewise a Teachers set may contain all the teachers of a school from all faculties. Entity sets need not be disjoint.
Attributes
Entities are represented by means of their properties, called attributes. All attributes have values. For example, a student entity may have name, class, and age as attributes.
There exists a domain or range of values that can be assigned to attributes. For example, a student's name cannot be a numeric value. It has to be alphabetic. A student's age cannot be negative, etc.
Types of Attributes
Simple attribute − Simple attributes are atomic values, which cannot be divided further. For example, a student's phone number is an atomic value of 10 digits.
Composite attribute − Composite attributes are made of more than one simple attribute. For example, a student's complete name may have first_name and last_name.
Derived attribute − Derived attributes are the attributes that do not exist in the physical database, but their values are derived from other attributes present in the database. For example, average_salary in a department should not be saved directly in the database, instead it can be derived. For another example, age can be derived from data_of_birth.
Single-value attribute − Single-value attributes contain single value. For example − Social_Security_Number.
Multi-value attribute − Multi-value attributes may contain more than one values. For example, a person can have more than one phone number, email_address, etc.
These attribute types can come together in a way like −
simple single-valued attributes
simple multi-valued attributes
composite single-valued attributes
composite multi-valued attributes
Entity-Set and Keys
Key is an attribute or collection of attributes that uniquely identifies an entity among entity set.
For example, the roll_number of a student makes him/her identifiable among students.
Super Key − A set of attributes (one or more) that collectively identifies an entity in an entity set.
Candidate Key − A minimal super key is called a candidate key. An entity set may have more than one candidate key.
Primary Key − A primary key is one of the candidate keys chosen by the database designer to uniquely identify the entity set.
Relationship
The association among entities is called a relationship. For example, an employee works_at a department, a student enrolls in a course. Here, Works_at and Enrolls are called relationships.
Relationship Set
A set of relationships of similar type is called a relationship set. Like entities, a relationship too can have attributes. These attributes are called descriptive attributes.
Degree of Relationship
The number of participating entities in a relationship defines the degree of the relationship.
Binary = degree 2
Ternary = degree 3
n-ary = degree
Mapping Cardinalities
Cardinality defines the number of entities in one entity set, which can be associated with the number of entities of other set via relationship set.
One-to-one − One entity from entity set A can be associated with at most one entity of entity set B and vice versa.
One-to-many − One entity from entity set A can be associated with more than one entities of entity set B however an entity from entity set B, can be associated with at most one entity.
Many-to-one − More than one entities from entity set A can be associated with at most one entity of entity set B, however an entity from entity set B can be associated with more than one entity from entity set A.
Many-to-many − One entity from A can be associated with more than one entity from B and vice versa.




Entity
Entities are represented by means of rectangles. Rectangles are named with the entity set they represent.
Attributes
Attributes are the properties of entities. Attributes are represented by means of ellipses. Every ellipse represents one attribute and is directly connected to its entity (rectangle).

If the attributes are composite, they are further divided in a tree like structure. Every node is then connected to its attribute. That is, composite attributes are represented by ellipses that are connected with an ellipse.

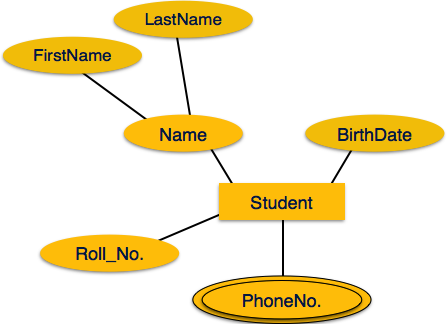
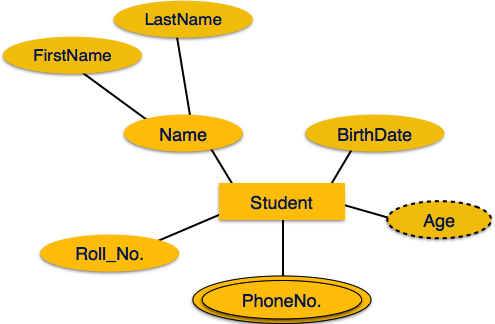
Multivalued attributes are depicted by double ellipse.
Derived attributes are depicted by dashed ellipse.
Relationship
Relationships are represented by diamond-shaped box. Name of the relationship is written inside the diamond-box. All the entities (rectangles) participating in a relationship, are connected to it by a line.
Binary Relationship and Cardinality
A relationship where two entities are participating is called a binary relationship. Cardinality is the number of instance of an entity from a relation that can be associated with the relation.
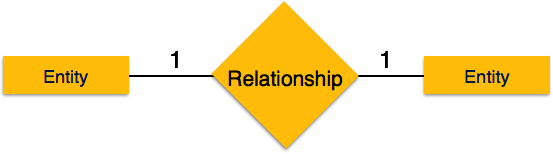
One-to-one − When only one instance of an entity is associated with the relationship, it is marked as '1:1'. The following image reflects that only one instance of each entity should be associated with the relationship. It depicts one-to-one relationship.
One-to-many − When more than one instance of an entity is associated with a relationship, it is marked as '1:N'. The following image reflects that only one instance of entity on the left and more than one instance of an entity on the right can be associated with the relationship. It depicts one-to-many relationship.
Many-to-one − When more than one instance of entity is associated with the relationship, it is marked as 'N:1'. The following image reflects that more than one instance of an entity on the left and only one instance of an entity on the right can be associated with the relationship. It depicts many-to-one relationship.
Many-to-many − The following image reflects that more than one instance of an entity on the left and more than one instance of an entity on the right can be associated with the relationship. It depicts many-to-many relationship.



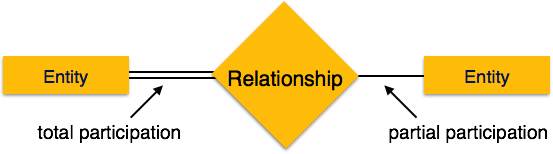
Participation Constraints
Total Participation − Each entity is involved in the relationship. Total participation is represented by double lines.
Partial participation − Not all entities are involved in the relationship. Partial participation is represented by single lines.
The ER Model has the power of expressing database entities in a conceptual hierarchical manner. As the hierarchy goes up, it generalizes the view of entities, and as we go deep in the hierarchy, it gives us the detail of every entity included.
Going up in this structure is called generalization, where entities are clubbed together to represent a more generalized view. For example, a particular student named Mira can be generalized along with all the students. The entity shall be a student, and further, the student is a person. The reverse is called specialization where a person is a student, and that student is Mira.
Generalization
As mentioned above, the process of generalizing entities, where the generalized entities contain the properties of all the generalized entities, is called generalization. In generalization, a number of entities are brought together into one generalized entity based on their similar characteristics. For example, pigeon, house sparrow, crow and dove can all be generalized as Birds.

Specialization
Specialization is the opposite of generalization. In specialization, a group of entities is divided into sub-groups based on their characteristics. Take a group ‘Person’ for example. A person has name, date of birth, gender, etc. These properties are common in all persons, human beings. But in a company, persons can be identified as employee, employer, customer, or vendor, based on what role they play in the company.
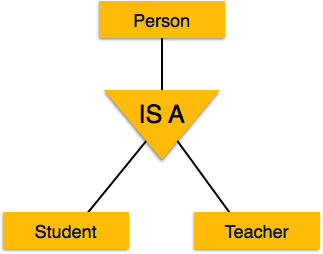
Similarly, in a school database, persons can be specialized as teacher, student, or a staff, based on what role they play in school as entities.
Inheritance
We use all the above features of ER-Model in order to create classes of objects in object-oriented programming. The details of entities are generally hidden from the user; this process known as abstraction.
Inheritance is an important feature of Generalization and Specialization. It allows lower-level entities to inherit the attributes of higher-level entities.
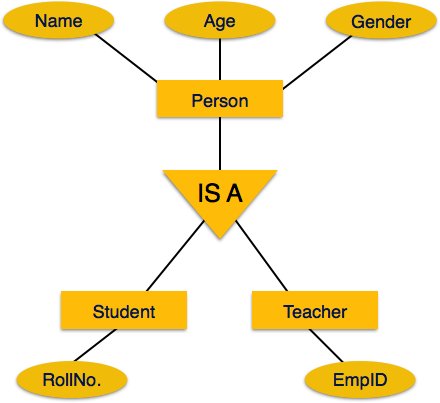
For example, the attributes of a Person class such as name, age, and gender can be inherited by lower-level entities such as Student or Teacher.
Concepts
Tables − In relational data model, relations are saved in the format of Tables. This format stores the relation among entities. A table has rows and columns, where rows represents records and columns represent the attributes.
Tuple − A single row of a table, which contains a single record for that relation is called a tuple.
Relation instance − A finite set of tuples in the relational database system represents relation instance. Relation instances do not have duplicate tuples.
Relation schema − A relation schema describes the relation name (table name), attributes, and their names.
Relation key − Each row has one or more attributes, known as relation key, which can identify the row in the relation (table) uniquely.
Attribute domain − Every attribute has some pre-defined value scope, known as attribute domain.
Relational Algebra
Relational algebra is a procedural query language, which takes instances of relations as input and yields instances of relations as output. It uses operators to perform queries. An operator can be either unary or binary. They accept relations as their input and yield relations as their output. Relational algebra is performed recursively on a relation and intermediate results are also considered relations.
The fundamental operations of relational algebra are as follows −
Select
Project
Union
Set different
Cartesian product
Rename
Select Operation (σ)
It selects tuples that satisfy the given predicate from a relation.
Notation − σp(r)
Where σ stands for selection predicate and r stands for relation. p is prepositional logic formula which may use connectors like and, or, and not. These terms may use relational operators like − =, ≠, ≥, < , >, ≤.
For example −
σsubject = "database"(Books)
Output − Selects tuples from books where subject is 'database'.
σsubject = "database" and price = "450"(Books)
Output − Selects tuples from books where subject is 'database' and 'price' is 450.
σsubject = "database" and price = "450" or year > "2010"(Books)
Output − Selects tuples from books where subject is 'database' and 'price' is 450 or those books published after 2010.
Project Operation (∏)
It projects column(s) that satisfy a given predicate.
Notation − ∏A1, A2, An (r)
Where A1, A2 , An are attribute names of relation r.
Duplicate rows are automatically eliminated, as relation is a set.
For example −
∏subject, author (Books)
Selects and projects columns named as subject and author from the relation Books.
Union Operation (∪)
It performs binary union between two given relations and is defined as −
r ∪ s = { t | t ∈ r or t ∈ s}
Notation − r U s
Where r and s are either database relations or relation result set (temporary relation).
For a union operation to be valid, the following conditions must hold −
r, and s must have the same number of attributes.
Attribute domains must be compatible.
Duplicate tuples are automatically eliminated.
∏ author (Books) ∪ ∏ author (Articles)
Output − Projects the names of the authors who have either written a book or an article or both.
Set Difference (−)
The result of set difference operation is tuples, which are present in one relation but are not in the second relation.
Notation − r − s
Finds all the tuples that are present in r but not in s.
∏ author (Books) − ∏ author (Articles)
Output − Provides the name of authors who have written books but not articles.
Cartesian Product (Χ)
Combines information of two different relations into one.
Notation − r Χ s
Where r and s are relations and their output will be defined as −
r Χ s = { q t | q ∈ r and t ∈ s}
σauthor = 'tutorialspoint'(Books Χ Articles)
Output − Yields a relation, which shows all the books and articles written by tutorialspoint.
Rename Operation (ρ)
The results of relational algebra are also relations but without any name. The rename operation allows us to rename the output relation. 'rename' operation is denoted with small Greek letter rho ρ.
Notation − ρ x (E)
Where the result of expression E is saved with name of x.
Additional operations are −
Set intersection
Assignment
Natural join
///////
Data Definition Language
SQL uses the following set of commands to define database schema −
CREATE
Creates new databases, tables and views from RDBMS.
For example −
Create database tutor;
Create table article;
Create view for_students;
DROP
Drops commands, views, tables, and databases from RDBMS.
For example−
Drop object_type object_name;
Drop database tutor;
Drop table article;
Drop view for_students;
ALTER
Modifies database schema.
Alter object_type object_name parameters;
For example−
Alter table article add subject varchar;
This command adds an attribute in the relation article with the name subjectof string type.
Data Manipulation Language
SQL is equipped with data manipulation language (DML). DML modifies the database instance by inserting, updating and deleting its data. DML is responsible for all froms data modification in a database. SQL contains the following set of commands in its DML section −
SELECT/FROM/WHERE
INSERT INTO/VALUES
UPDATE/SET/WHERE
DELETE FROM/WHERE
These basic constructs allow database programmers and users to enter data and information into the database and retrieve efficiently using a number of filter options.
SELECT/FROM/WHERE
SELECT − This is one of the fundamental query command of SQL. It is similar to the projection operation of relational algebra. It selects the attributes based on the condition described by WHERE clause.
FROM − This clause takes a relation name as an argument from which attributes are to be selected/projected. In case more than one relation names are given, this clause corresponds to Cartesian product.
WHERE − This clause defines predicate or conditions, which must match in order to qualify the attributes to be projected.
For example −
Select author_name
From book_author
Where age > 50;
This command will yield the names of authors from the relation book_authorwhose age is greater than 50.
INSERT INTO/VALUES
This command is used for inserting values into the rows of a table (relation).
Syntax−
INSERT INTO table (column1 [, column2, column3 ... ]) VALUES (value1 [, value2, value3 ... ])
Or
INSERT INTO table VALUES (value1, [value2, ... ])
For example −
INSERT INTO tutor (Author, Subject) VALUES ("anonymous", "computers");
UPDATE/SET/WHERE
This command is used for updating or modifying the values of columns in a table (relation).
Syntax −
UPDATE table_name SET column_name = value [, column_name = value ...] [WHERE condition]
For example −
UPDATE tutor SET Author="webmaster" WHERE Author="anonymous";
DELETE/FROM/WHERE
This command is used for removing one or more rows from a table (relation).
Syntax −
DELETE FROM table_name [WHERE condition];
For example −
DELETE FROM tutor
WHERE Author="unknown";
What is a KEY?
A KEY is a value used to identify a record in a table uniquely. A KEY could be a single column or combination of multiple columns
Note: Columns in a table that are NOT used to identify a record uniquely are called non-key columns.
What is a Primary Key?
A primary is a single column value used to identify a database record uniquely.
It has following attributes
A primary key cannot be NULL
A primary key value must be unique
The primary key values cannot be changed
The primary key must be given a value when a new record is inserted.
What is Composite Key?
A composite key is a primary key composed of multiple columns used to identify a record uniquely
In our database, we have two people with the same name Robert Phil, but they live in different places.
Foreign Key
Foreign Key references the primary key of another Table! It helps connect your Tables
A foreign key can have a different name from its primary key
It ensures rows in one table have corresponding rows in another
Unlike the Primary key, they do not have to be unique. Most often they aren't
Foreign keys can be null even though primary keys can not
Normalization
Normalization is a method to remove all these anomalies and bring the database to a consistent state.
What is Normalization?
Normalization is a database design technique which organizes tables in a manner that reduces redundancy and dependency of data.
It divides larger tables to smaller tables and links them using relationships.
1NF (First Normal Form) Rules
Each table cell should contain a single value.
Each record needs to be unique.
A table before normalization:

The above table after 1NF:

2NF (Second Normal Form) Rules
Rule 1- Be in 1NF
Rule 2- Single Column Primary Key
In 2nd Normalization form we have to partition the table above.


3NF (Third Normal Form) Rules
Rule 1- Be in 2NF
Rule 2- Has no transitive functional dependencies
To move our 2NF table into 3NF, we again need to again divide our table.
3NF Example



We have again divided our tables and created a new table which stores Salutations.
There are no transitive functional dependencies, and hence our table is in 3NF
In Table 3 Salutation ID is primary key, and in Table 1 Salutation ID is foreign to primary key in Table 3.
Boyce-Codd Normal Form (BCNF)
Even when a database is in 3rd Normal Form, still there would be anomalies resulted if it has more than one Candidate Key.
Sometimes is BCNF is also referred as 3.5 Normal Form.
4NF (Fourth Normal Form) Rules
If no database table instance contains two or more, independent and multivalued data describing the relevant entity, then it is in 4th Normal Form.
5NF (Fifth Normal Form) Rules
A table is in 5th Normal Form only if it is in 4NF and it cannot be decomposed into any number of smaller tables without loss of data.
What is ER Modeling?
Entity Relationship Modeling (ER Modeling) is a graphical approach to database design. It uses Entity/Relationship to represent real world objects.
An Entity is a thing or object in real world that is distinguishable from surrounding environment. For example each employee of an organization is a separate entity. Following are some of major characteristics of entities.
An entity has a set of properties.
Entity properties can have values.
Creating a database involves translating the logical database design model into the physical database.
MySQL supports a number of data types for numeric, dates and strings values.
CREATE DATABASE command is used to create a database
CREATE TABLE command is used to create tables in a database
Create Database
SQL SELECT statement
SELECT is the SQL keyword that lets the database know that you want to retrieve data.
FROM tableName is mandatory and must contain at least one table, multiple tables must be separated using commas or joined using the JOIN keyword.
WHERE condition is optional, it can be used to specify criteria in the result set returned from the query.
GROUP BY is used to put together records that have the same field values.
HAVING condition is used to specify criteria when working using the GROUP BY keyword.
ORDER BY is used to specify the sort order of the result set.
SELECT * FROM `members`;
SELECT * FROM tableName WHERE condition;
"SELECT * FROM tableName" is the standard SELECT statement
"WHERE" is the keyword that restricts our select query result set and "condition" is the filter to be applied on the results. The filter could be a range, single value or sub query.
WHERE clause combined with - AND LOGICAL Operator
SELECT * FROM `movies` WHERE `category_id` = 2 AND `year_released` = 2008;
What is INSERT INTO?
INSERT INTO `table_name`(column_1,column_2,...) VALUES (value_1,value_2,...);
INSERT INTO `table_name` is the command that tells MySQL server to add new row into a table named `table_name`.
(column_1,column_2,...) specifies the columns to be updated in the new row
VALUES (value_1,value_2,...) specifies the values to be added into the new row
What is the DELETE Keyword?
DELETE FROM `table_name` [WHERE condition];
DELETE FROM `table_name` tells MySQL server to remove rows from the table ..
[WHERE condition] is optional and is used to put a filter that restricts the number of rows affected by the DELETE query.
Update command syntax
The basic syntax of the SQL Update command is as shown below.
UPDATE `table_name` SET `column_name` = `new_value' [WHERE condition];
UPDATE `table_name` is the command that tells MySQL to update the data in a table .
SET `column_name` = `new_value' are the names and values of the fields to be affected by the update query. Note, when setting the update values, strings data types must be in single quotes. Numeric values do not need to be in quotation marks. Date data type must be in single quotes and in the format 'YYYY-MM-DD'.
[WHERE condition] is optional and can be used to put a filter that restricts the number of rows affected by the UPDATE query.
Alter- syntax
The basic syntax used to add a column to an already existing table is shown below
ALTER TABLE `table_name` ADD COLUMN `column_name` `data_type`;
"ALTER TABLE `table_name`" is the command that tells MySQL server to modify the table named `table_name`.
"ADD COLUMN `column_name` `data_type`" is the command that tells MySQL server to add a new column named `column_name` with data type `data_type'.
WHAT IS THE DROP COMMAND?
The DROP command is used to
Delete a database from MySQL server
Delete an object (like Table , Column)from a database.
What is a union?
Unions combine the results from multiple SELECT queries into a consolidated result set.
The only requirements for this to work is that the number of columns should be the same from all the SELECT queries which needs to be combined .
Suppose we have two tables as follows

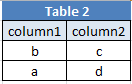
Let's now create a UNION query to combines both tables using DISTINCT
SELECT `column1`,` column1FROM `table1`
UNION DISTINCT
SELECT ` column1`,` column1` FROM `table2`;
Here duplicate rows are removed and only unique rows are returned.

The UNION command is used to combine more than one SELECT query results into a single query contain rows from all the select queries.
The number of columns and data types in the SELECT statements must be the same in order for the UNION command to work.
The DISTINCT clause is used to eliminate duplicate values from the UNION query result set. MySQL uses the DISTINCT clause as the default when executing UNION queries if nothing is specified.
The ALL clause is used to return all even the duplicate rows in the UNION query.
What are JOINS?
Joins help retrieving data from two or more database tables.
The tables are mutually related using primary and foreign keys.
Types of joins
Cross JOIN
Cross JOIN is a simplest form of JOINs which matches each row from one database table to all rows of another.
In other words it gives us combinations of each row of first table with all records in second table.
Suppose we want to get all member records against all the movie records, we can use the script shown below to get our desired results.

SELECT * FROM `movies` CROSS JOIN `members`
INNER JOIN
The inner JOIN is used to return rows from both tables that satisfy the given condition.
Suppose , you want to get list of members who have rented movies together with titles of movies rented by them. You can simply use an INNER JOIN for that, which returns rows from both tables that satisfy with given conditions.

SELECT members.`first_name` , members.`last_name` , movies.`title`
FROM members ,movies
WHERE movies.`id` = members.`movie_id`
LEFT JOIN
Assume now you want to get titles of all movies together with names of members who have rented them. It is clear that some movies have not being rented by any one. We can simply use LEFT JOIN for the purpose.

The LEFT JOIN returns all the rows from the table on the left even if no matching rows have been found in the table on the right. Where no matches have been found in the table on the right, NULL is returned.
RIGHT JOIN
RIGHT JOIN is obviously the opposite of LEFT JOIN. The RIGHT JOIN returns all the columns from the table on the right even if no matching rows have been found in the table on the left. Where no matches have been found in the table on the left, NULL is returned.
In our example, let's assume that you need to get names of members and movies rented by them. Now we have a new member who has not rented any movie yet

SELECT A.`first_name` , A.`last_name`, B.`title`
FROM `members` AS A
RIGHT JOIN `movies` AS B
ON B.`id` = A.`movie_id`
Transaction
A transaction can be defined as a group of tasks. A single task is the minimum processing unit which cannot be divided further.
A transaction is a very small unit of a program and it may contain several low level tasks. A transaction in a database system must maintain Atomicity, Consistency, Isolation, and Durability − commonly known as ACID properties − in order to ensure accuracy, completeness, and data integrity.
Atomicity − This property states that a transaction must be treated as an atomic unit, that is, either all of its operations are executed or none. There must be no state in a database where a transaction is left partially completed. States should be defined either before the execution of the transaction or after the execution/abortion/failure of the transaction.
Consistency − The database must remain in a consistent state after any transaction. No transaction should have any adverse effect on the data residing in the database. If the database was in a consistent state before the execution of a transaction, it must remain consistent after the execution of the transaction as well.
Durability − The database should be durable enough to hold all its latest updates even if the system fails or restarts. If a transaction updates a chunk of data in a database and commits, then the database will hold the modified data. If a transaction commits but the system fails before the data could be written on to the disk, then that data will be updated once the system springs back into action.
Isolation − In a database system where more than one transaction are being executed simultaneously and in parallel, the property of isolation states that all the transactions will be carried out and executed as if it is the only transaction in the system. No transaction will affect the existence of any other transaction.
Serializability
When multiple transactions are being executed by the operating system in a multiprogramming environment, there are possibilities that instructions of one transactions are interleaved with some other transaction.
Schedule − A chronological execution sequence of a transaction is called a schedule. A schedule can have many transactions in it, each comprising of a number of instructions/tasks.
Serial Schedule − It is a schedule in which transactions are aligned in such a way that one transaction is executed first. When the first transaction completes its cycle, then the next transaction is executed. Transactions are ordered one after the other. This type of schedule is called a serial schedule, as transactions are executed in a serial manner.
Equivalence Schedules
An equivalence schedule can be of the following types −
Result Equivalence
If two schedules produce the same result after execution, they are said to be result equivalent. They may yield the same result for some value and different results for another set of values. That's why this equivalence is not generally considered significant.
View Equivalence
Two schedules would be view equivalence if the transactions in both the schedules perform similar actions in a similar manner.
For example −
If T reads the initial data in S1, then it also reads the initial data in S2.
If T reads the value written by J in S1, then it also reads the value written by J in S2.
If T performs the final write on the data value in S1, then it also performs the final write on the data value in S2.
Conflict Equivalence
Two schedules would be conflicting if they have the following properties −
Both belong to separate transactions.
Both accesses the same data item.
At least one of them is "write" operation.
Two schedules having multiple transactions with conflicting operations are said to be conflict equivalent if and only if −
Both the schedules contain the same set of Transactions.
The order of conflicting pairs of operation is maintained in both the schedules.
Note − View equivalent schedules are view serializable and conflict equivalent schedules are conflict serializable. All conflict serializable schedules are view serializable too.
States of Transactions
A transaction in a database can be in one of the following states −

{kind=link}
Active − In this state, the transaction is being executed. This is the initial state of every transaction.
Partially Committed − When a transaction executes its final operation, it is said to be in a partially committed state.
Failed − A transaction is said to be in a failed state if any of the checks made by the database recovery system fails. A failed transaction can no longer proceed further.
Aborted − If any of the checks fails and the transaction has reached a failed state, then the recovery manager rolls back all its write operations on the database to bring the database back to its original state where it was prior to the execution of the transaction. Transactions in this state are called aborted. The database recovery module can select one of the two operations after a transaction aborts −
Re-start the transaction
Kill the transaction
Committed − If a transaction executes all its operations successfully, it is said to be committed. All its effects are now permanently established on the database system.
Concurrency control protocols can be broadly divided into two categories −
Lock based protocols
Time stamp based protocols
Lock-based Protocols
Database systems equipped with lock-based protocols use a mechanism by which any transaction cannot read or write data until it acquires an appropriate lock on it. Locks are of two kinds −
Binary Locks − A lock on a data item can be in two states; it is either locked or unlocked.
Shared/exclusive − This type of locking mechanism differentiates the locks based on their uses. If a lock is acquired on a data item to perform a write operation, it is an exclusive lock. Allowing more than one transaction to write on the same data item would lead the database into an inconsistent state. Read locks are shared because no data value is being changed.
No comments:
Post a Comment